

实战破解百度贴吧验证码
- 时间:2015年04月02日 15:29:36 来源:魔法猪系统重装大师官网 人气:9812



百度贴吧的验证码如下图所示
http://tieba.baidu.com/f?kw=Discuz&ie=utf-8&fr=wwwt#sub
![]()
验证码地址:
http://tieba.baidu.com/cgi-bin/genimg?001346816261017068F482CC523E71D14DBDE68008A85D1D5B0C605AFC192703D2230279F54F92B2A69BDA3A2AAA6B744F44FC8593E0D56DA2E98129D837F29CD1464B9723EBB4C3D32A5841330AE96165BF05D56C7B9B0B3A5719BB6C7166492651D0FFB514DCAECBC4433E2C529233B2DAE5F44ACE4421193C4CE0E4B0A2E1CD89EBBCC5DCE94D0E8A8D104F639DA712D3F05F72C10F20FFB16EF1FDEE5E8B04BDD6255DE1ADB1720147A1C58891723693DE44FA23A8D8&t=0.7780897873062544
刷新一下就会变成新的字符。
捣鼓了一两天的时间,对于手动分割好的单个字符的识别准确率倒是不低,不过始终没能很好的解决粘连字符的分割问题,后来就放下了。
这两天一同学让帮忙破解一网站的验证码,瞅了下是比较传统的数字验证码,而且无粘连、扭曲、倾斜,于是就开始着手破解了。
要识别的验证码如下图所示:
![]()
![]()
![]()
![]()
从上面的验证码可以看出,破解的工作无需考虑字符的分割问题,而只需将精力花在背景的去除上。乍一看,每个字符周围的背景杂点都跟字符的颜色很接近,看上去不太容易过滤调背景杂点而只保留字符本身,实际上做起来也不容易。起初考虑过几种阈值化处理操作,可处理后的结果一点也不理想。几次尝试失败之后,考虑到此种验证码主要是在前景与背景的颜色上做文章,于是我打算分析验证码的颜色分布直方图,看能不能找出突破口。由于每个字符周围的杂点颜色跟该字符的颜色相关,而与其他字符的颜色无关,所以我接下来的颜色直方图的分析都只是针对分割后的单个字符。
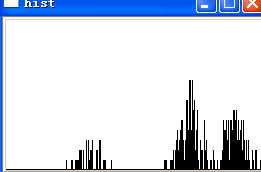
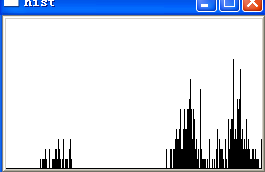
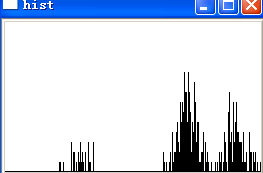
就拿![]() 举例吧,分割后的每个字符所对应的颜色直方图如下图所示:
举例吧,分割后的每个字符所对应的颜色直方图如下图所示:
![]()
↓↓ 
![]()
↓↓
![]()
↓↓
![]()
↓↓
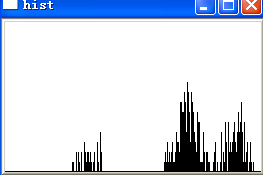
画出每个字符的颜色分布直方图之后,一眼便看出了验证码背后存在某种规律。进一步分析可得知,直方图左侧孤立的小块区域正是字符本身的颜色,而右侧的大块区域则全是背景杂色,因此只要我们得出直方图左侧块的颜色范围,便可去除非字符本身的杂点,至于这个范围的获取想必不会有人会认为是难事。
去除背景并进行图像二值化后就会得到下图所示的字符图片:
![]() ->
-> ![]()
![]() ->
-> ![]()
![]() ->
-> ![]()
![]() ->
-> ![]()
接下来要做的事情便是识别这些无背景杂点的二值图像字符,方法有很多,我用的是机器学习的方法,背景去除成功的情况下的识别率基本接近于100%。




