图示SupeSite7.0采集教程
- 时间:2015年04月02日 10:59:59 来源:魔法猪系统重装大师官网 人气:6714



SupeSite7.0 添加了很多自动识别功能,采集起来也是非常简单,主要填写 4 个地方就可以了。
图示,SupeSite7.0,采集,教程,SupeSite7
以采集: http://ent.163.com/special/00031HA4/morenews_02.html 为例。
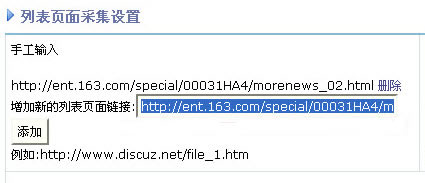
填写要采集的地址到图1的地方。
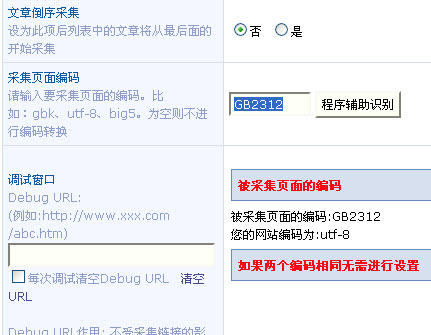
如果采集的页面和网站的不一样,需要填写下编码,你只需要点击【程序辅助识别】,把识别出来的填写到图2的位置。
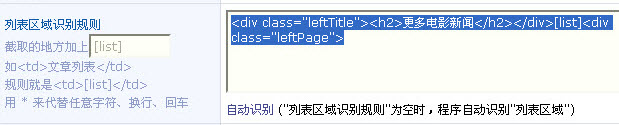
列表区域识别规则:查看文件源码。复制你要采集的第一篇文章,查找源码,图3。

再向上随便找一个代码(中文也可以),但是要独一无二的,怎么才是独一无二的呢?同样查找,把代码放进去,图4查找上一个,再查找下一个,如果发现都找不到,这个就是独一无二的,继续复制要采集的最后一篇文章的标题查找到后,往下找一个独一无二的代码然后填写到图5,中间代码使用 [list] 替换。

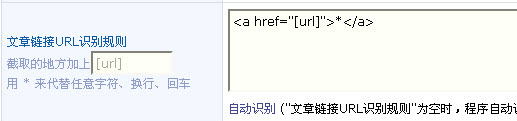
文章链接 URL 识别规则:复制文章的链接图6,放到图7位置,按左边说明进行替换,网址使用 [url] 替换。

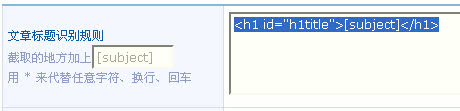
文章标题识别规则:复制文章标题进行查找,不要找 这里的,选另一个地方的,复制到图8的位置,也是按左边的规则进行替换。标题文章使用 [subject] 替换。
文章内容识别规则:和列表区域识别规则一样,找文章的第一句话和最后一句话,然后上下找独一无二的代码,填写在图9的位置。文章内容使用 [message] 替换。

这样采集规则就写好了,点击提交保存。页面跳转后,点击开始采集 图10。

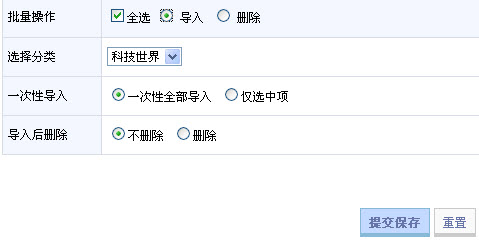
点击【采集完成,点击此处查看采集结果】,全选导入到你想要的板块 图11。
还需要更新下缓存,系统管理、更新缓存 图12。